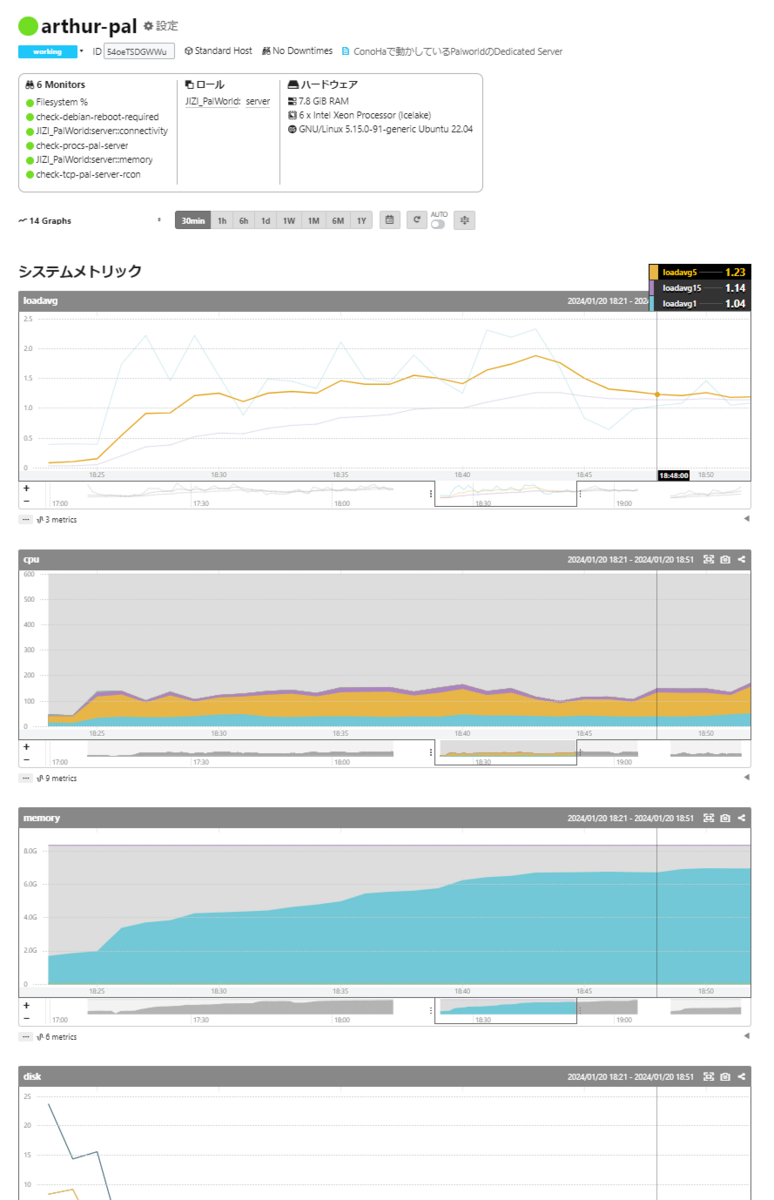
mackerel-agentをコマンド1つでインストールすると、ホストが登録されMackerel上で以下のようにホストのシステムメトリックのグラフを閲覧することができます。最速便利。
さて、メトリックを収集する仕組みはOpenTelemetryという標準規格に統一されようとする世の中の流れがあります。Mackerelとしてもこの標準に乗っかっていく、さらにメトリックにラベルという概念を加えてより自在に引けるようにすることを目指して、OpenTelemetry対応を進めています。現在ベータテスト中ですので、ぜひお試しください。
今回は、mackerel-agentをインストールしてできるシステムメトリックのグラフを、Mackerelのラベル付きメトリック機能とOpenTelemetry Collectorを使ってできる限り再現してみることにします。
メトリックの収集
OpenTelemetry Collectorのインストール
以下の記事に従ってOpenTelemetry Collectorをインストールします。
ただし、今回はcontrib版に入っているReceiverやProcessorを利用したいので、以下のようにパッケージのURLを変更しておきます。
# debの場合 sudo apt-get update sudo apt-get -y install wget systemctl -wget https://github.com/open-telemetry/opentelemetry-collector-releases/releases/download/v0.92.0/otelcol_0.92.0_linux_amd64.deb +wget https://github.com/open-telemetry/opentelemetry-collector-releases/releases/download/v0.92.0/otelcol-contrib_0.92.0_linux_amd64.deb -sudo dpkg -i otelcol_0.92.0_linux_amd64.deb +sudo dpkg -i otelcol-contrib_0.92.0_linux_amd64.deb
設定ファイルの記述
インストールができたら、Collectorの設定ファイルである/etc/otelcol-contrib/config.yamlを編集して以下のように記述します。
receivers: hostmetrics: collection_interval: 60s scrapers: cpu: disk: load: filesystem: memory: network: processors: batch: timeout: 1m resourcedetection: detectors: ["system"] system: hostname_sources: ["os"] exporters: otlp/mackerel: endpoint: otlp.mackerelio.com:4317 compression: gzip headers: Mackerel-Api-Key: ***censored*** service: pipelines: metrics: receivers: [hostmetrics] processors: [resourcedetection, batch] exporters: [otlp/mackerel]
上のブロックから順に解説します。
ホストのメトリックを取得するには、Host Metrics Receiverを利用します。Mackerelのメトリックの最小粒度は1分なので、1分ごとメトリックを取得するように collection_interval: 60s と設定しておきます。scrapersに指定できる取得対象はもっとたくさんあるのですが、mackerel-agentがデフォルトで取得するメトリックに合わせておきました。
Resource Detection Processorを使うことで、投稿されるメトリックに属性(ラベル)を付与することができます。逆にこれがないと、投稿したメトリックをホストごと区別できない(あるいは別の方法で属性をつけなければならない)ことになります。今回の設定では、OSに設定されているホスト名を見て、host.name="arthur-pal"のようにホスト名を属性として付与してくれます。
MackerelにOpenTelemetry Metricsを投稿する際に利用するのは、OpenTelemetry Protocol Exporterです。MackerelはOTLPをサポートしているので、OpenTelemetry標準のエクスポーターをそのまま利用できます。headersにMackerelのAPIキーを入れて認証します。
最後にこれらの設定をservice.pipelines.metricsでまとめて完成です。
メトリックの描画
OTLPでMackerelに投稿したメトリックはPromQLライクな言語でクエリをかけてグラフとして描画することができます。PromQLで作ったグラフでシステムメトリックのグラフを再現していきます。
loadavg
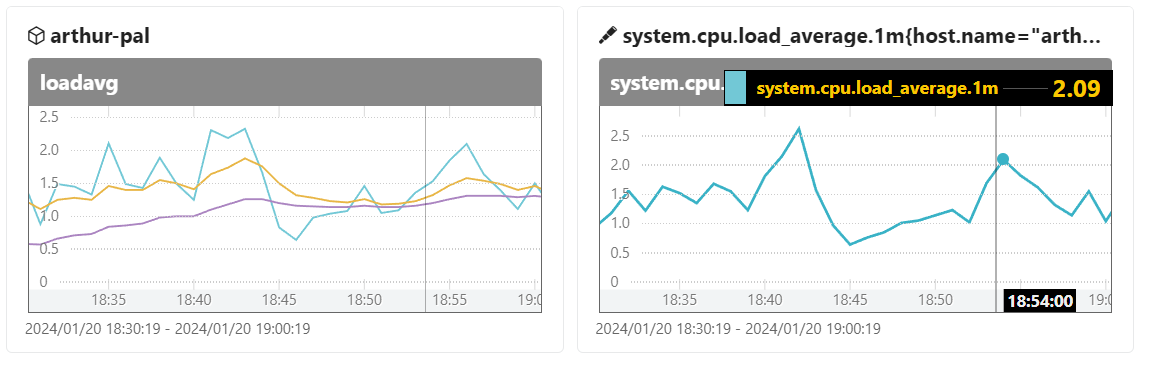
system.cpu.load_average.1m{host.name="arthur-pal"}
メトリック名だけだとどのホストかを絞り込めないので、{host.name="arthur-pal"}というラベルマッチャを書いています。
cpu
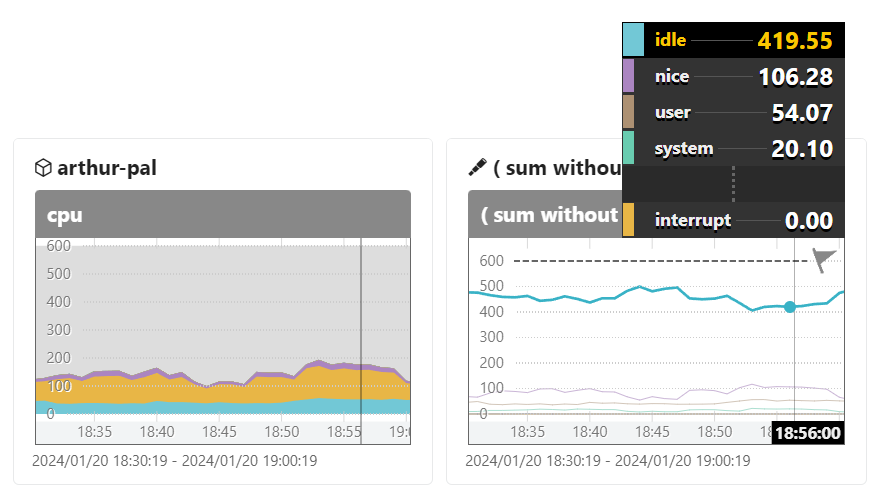
sum without (cpu) (irate(system.cpu.time{host.name="arthur-pal"}[2m]))
/ (
scalar(sum without (cpu) (irate(system.cpu.time{host.name="arthur-pal",state="user"}[2m])))
+ scalar(sum without (cpu) (irate(system.cpu.time{host.name="arthur-pal",state="nice"}[2m])))
+ scalar(sum without (cpu) (irate(system.cpu.time{host.name="arthur-pal",state="system"}[2m])))
+ scalar(sum without (cpu) (irate(system.cpu.time{host.name="arthur-pal",state="idle"}[2m])))
)
* 600
左が積み上げグラフなのに対し、クエリグラフでは積み上げに対応していないので分かりづらいですが、値はほぼ一致しています。6コアなので×600しているところが微妙なのでなんとかしたいですね。
memory
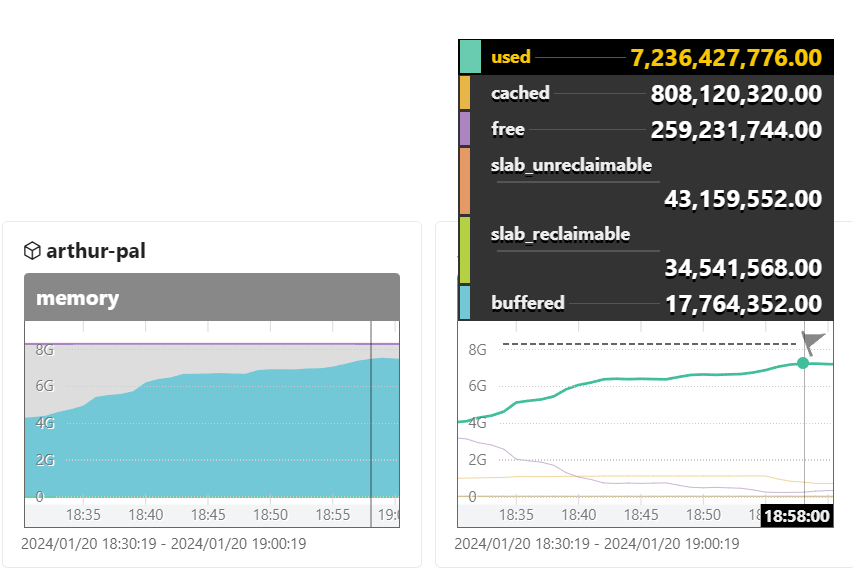
system.memory.usage{host.name="arthur-pal"}
disk
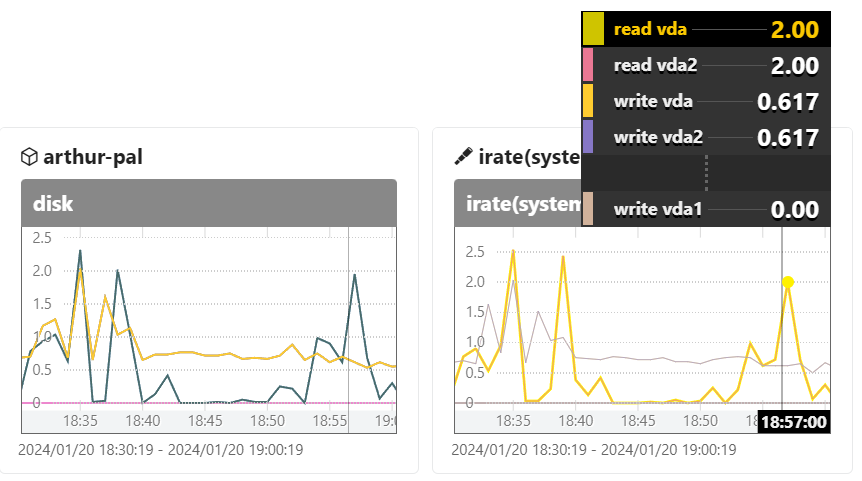
irate(system.disk.operations{host.name="arthur-pal"}[2m])
system.disk.operationsは単調増加していくカウンタなので、範囲ベクトルとして取得した上でirate()関数でwrapすると、1秒あたりの増加率として値が得られます。
interface
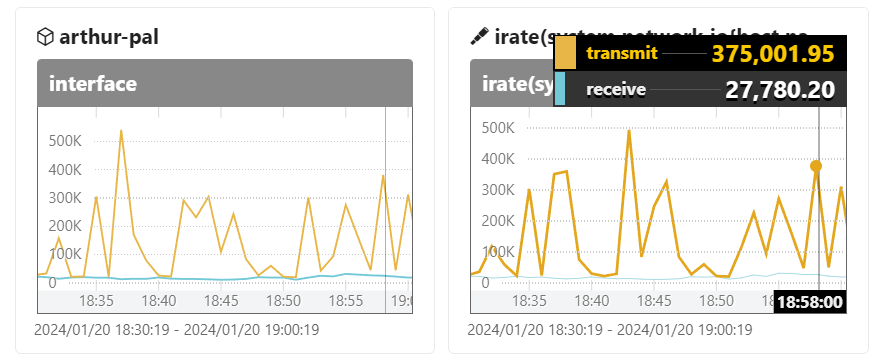
irate(system.network.io{host.name="arthur-pal", device="eth0"}[2m])
device名を指定していますが、 sum without (device) irate(system.network.io{host.name="arthur-pal", device="eth0"}[2m]) としてデバイスごとの値を合算してしまったほうが良いのかもしれません。
filesystem
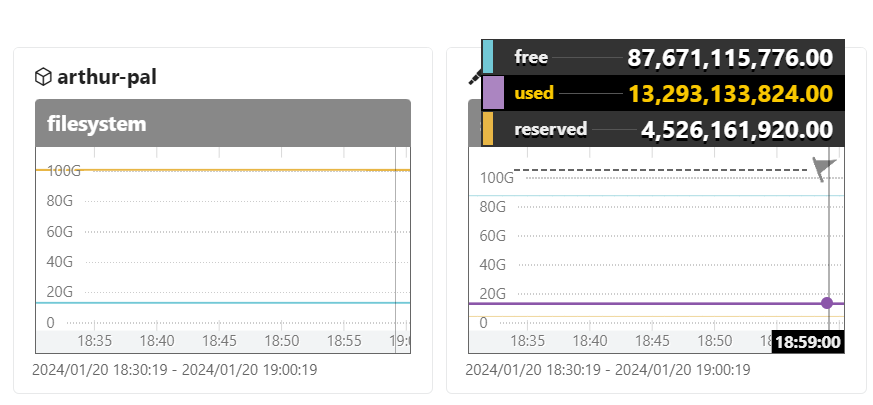
system.filesystem.usage{host.name="arthur-pal",device="/dev/vda2"}
ということで、mackerel-agentが取得するシステムメトリックのグラフを、OpenTelemetry Collectorで取得したメトリックのグラフとして再現することができました!PromQLを書くのは慣れないと大変なので、このあたりの支援ができたらより便利になりそうですね。